Rearchitecting Classification Frameworks For Increased Robustness
We enforce invariances found in objects to improve the robustness accuracy trade-off found in Deep Neural Networks (DNNs). Our evaluation is performed using multiple adversarial defenses across various domain specific tasks (traffic sign classification and speaker recognition) as well as the general case of image classification.
Find our paper at https://arxiv.org/abs/1905.10900
See our code at https://github.com/byron123t/3d-adv-pc and https://github.com/byron123t/YOPO-You-Only-Propagate-Once
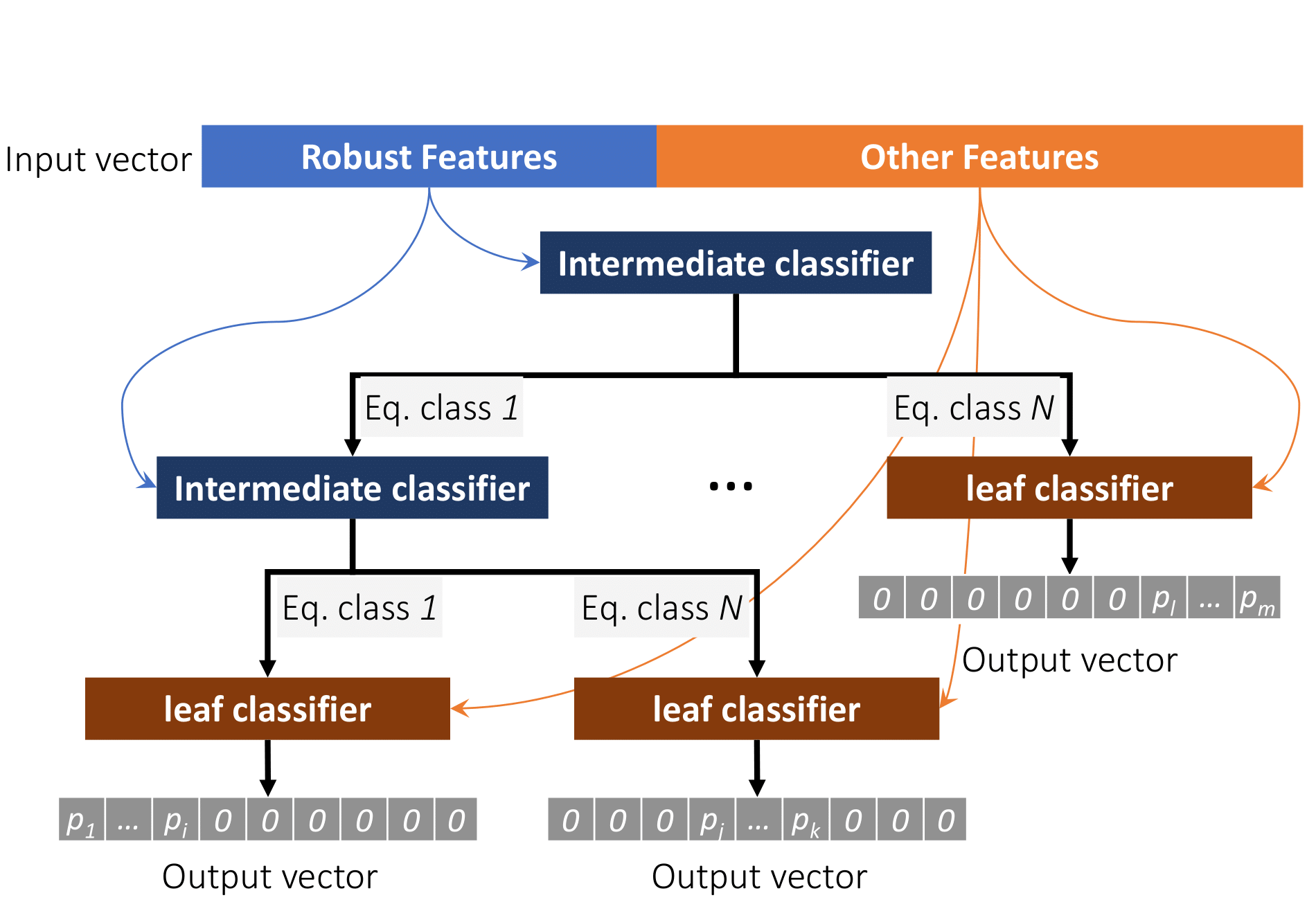 Our high level design of a hierarchical architecture which enforces robust features or invariances
Our high level design of a hierarchical architecture which enforces robust features or invariances
Theoretical Analysis of Randomized Smoothing
Recent advances in machine learning (ML) algorithms, especially deep neural networks (DNNs), have demonstrated remarkable success (sometimes exceeding human-level performance) on several tasks, including face and speech recognition. However, ML algorithms are vulnerable to adversarial attacks, such test-time, training-time, and backdoor attacks. In test-time attacks an adversary crafts adversarial examples, which are specially crafted perturbations imperceptible to humans which, when added to an input example, force a machine learning model to misclassify the given input example.
Adversarial examples are a concern when deploying ML algorithms in critical contexts, such as information security and autonomous driving. Researchers have responded with a plethora of defenses. One promising defense is randomized smoothing in which a classifier’s prediction is smoothed by adding random noise to the input example we wish to classify.
In this paper, we theoretically and empirically explore randomized smoothing. We investigate the effect of randomized smoothing on the feasible hypotheses space, and show that for some noise levels the set of hypotheses which are feasible shrinks due to smoothing, giving one reason why the natural accuracy drops after smoothing. To perform our analysis, we introduce a model for randomized smoothing which abstracts away specifics, such as the exact distribution of the noise. We complement our theoretical results with extensive experiments.
DARPA Guaranteeing AI Robustness Against Deception (GARD)
Military deception has been a subject of interest to the Department of Defense, and its predecessors since before the dawn of the modern computer: Sun Tzu’s The Art of War, which dates to before the common era (before year 0) discusses deception as a military tactic. The allies famously carried out large-scale military deception during World War II in the form of Operation Bodyguard. WIth the use of dummy military vehicles and simulated radio traffic, Operation Bodyguard succeeded in diverting the attention of Axis forces away from Normandy, the site of D-Day landings, to Pas-De-Calais, the department of France closest to Britain.
Modern reconnaissance techniques yield an abundance of data, far too large for human analysts to carefully sort through its entirety in an unaided fashion. Computerized image recognition systems have the potential to reduce the burden on human intelligence analysts, but in their current state, such systems are vulnerable acts of deception similar to those undertaken by the Allies during Operation Bodyguard.
In this DARPA-funded project, we leverage our knowledge of adversarial attacks against computational image systems, and our knowledge of defenses against such attacks, to design and experiment with systems more robust to military deception. WIth robust computerized image recognition systems at their disposal, the strain on human intelligence analysts can be reduced.
Fairness in Machine Learning
As machine learning systems have exhibited exemplary performance across a wide variety of tasks, the scope of their use has broadened to include decision-making in insurance, healthcare, education, financial, and legal settings. This intertwining of society and machine learning has surfaced the issue of fairness of such machine learning systems. As such, machine learning systems have been the subject of increasing controversy, including: software designed to predict recidivism being accused of racial discrimination and social media being accused of shadow banning.
Machine learning fairness is a formalism with which we study the disparate impact of machine learning systems. In particular, machine learning fairness studies whether a given predictor achieves performance parity with respect to a sensitive attribute at the individual or group level.
In this research thrust, we study the interplay between fairness and privacy of face obfuscation systems. We also study sample complexities for multicalibration error, a quantity used to capture group fairness of machine learning systems.
One such work under the fairness in machine learning umbrella is an evaluation of face obfuscation systems such as Face-Off. In this work, we show metric embedding networks — the core machinery underlying many face recognition systems — are demographically aware. In particular, face embeddings generated by the metric embedding network are clustered by demographic. This phenomenon exists even though metric embedding networks do not have explicit access to demographic information. We show, through extensive evaluation and and an intuitive analytical mode, how such demographic awareness can lead to reduced face obfuscation utility.