Towards More Robust Keyword Spotting for Voice Assistants
Voice activated devices such as Google Home and Amazon’s Echo are increasingly pervasive in households. As of 2019, about 35% of U.S. households are equipped with at least one voice assistant and this rate is expected to increase to about 75% by 2025. Voice Assistants (VA) offer their users a hands-free natural interaction via voice which is preferable in many situations. However, they bring in crucial security and privacy implications. It is unprecedented to have an always listening device in our most private and intimate spaces, potentially recording private conversations and sending them to the cloud. Moreover, voice assistants collect sensitive information like credit card data and bank accounts, and control physical smart home devices such as the lights, garage door, and other smart appliances. Compromising the VA by a malicious activation gives the adversary access to all the powerful controls the VA possesses.
In this project, we explore the significant privacy and security threats that results from the poor precision of the local (on-device) keyword spotting (KWS) model of the voice assistant (VA) under two threat models. First, our experiments demonstrate that accidental activations result in up to a minute of speech recording being uploaded to the cloud. Second, we verify that adversaries can systematically trigger misactivations through adversarial examples, which exposes the integrity and availability of services connected to the voice assistant.
We propose EKOS (Ensemble for KeywOrd Spotting) which leverages the semantics of the KWS task to defend against both accidental and adversarial activations. EKOS incorporates spatial redundancy from the acoustic environment at training and inference time to minimize distribution drifts responsible for accidental activations. It also exploits a physical property of speech (its redundancy at different harmonics) to deploy an ensemble of models trained on different harmonics and provably force the adversary to modify more of the frequency spectrum to obtain adversarial examples.
Our evaluation shows that EKOS increases the cost of adversarial activations while preserving the natural accuracy. We validate the performance of EKOS with over-the-air experiments on commodity devices and commercial voice assistants; we find that EKOS improves the precision of the KWS task in non-adversarial settings.
 EKOS implemented using 5 Echo devices.
EKOS implemented using 5 Echo devices.
Shimaa Ahmed, Ilia Shumailov, Nicolas Papernot, and Kassem Fawaz. Towards More Robust Keyword Spotting for Voice Assistants. In 30th USENIX Security Symposium (USENIX Security 22), Aug 2022. [pdf] [Github] [Dataset]
Privacy-Enhancing Technique for Eye Tracking in Mixed Reality
We are seeking to bridge the gap of user privacy in human-centered sensing. Eye tracking enables a more immersive experience for today’s user interface, while its rich information is exposed, inducing privacy concerns about users’ interest, health, identity, etc. Through the on-going project, we are exploring the opportunity to design real-time privacy control knob for eye-tracking in mixed-reality.
Pr$\epsilon\epsilon$ch: A System for Privacy-Preserving Speech Transcription
Speech Transcription has become a commercially mature technology that automates the transcription of continuous speech. Cloud services possess highly accurate and scalable speech transcription models as a part of the machine learning as a service (MLaaS) business model. This service is very convenient for many applications such as journalism, education, conference meetings, and health care documentation. However, speech is a rich source of sensitive acoustic and textual information; hence, using cloud services poses significant privacy threats to the users. Although offline systems eliminates the privacy risks, we found that its transcription performance is inferior to that of cloud-based systems, especially for real-world use cases.
In this project, we propose Pr$\epsilon\epsilon$ch, an end-to-end speech transcription system which lies at an intermediate point in the privacy-utility spectrum. It relies on cloud-based services to transcribe a speech file after applying a series of privacy-preserving operations on the user’s side. These operations protect the acoustic features of the speakers’ voices and protect the privacy of the textual content at an improved performance relative to the offline system, Deep Speech. Additionally, Pr$\epsilon\epsilon$ch provides several control knobs to customize the utility-usability-privacy trade-off. We perform a comprehensive evaluation of Pr$\epsilon\epsilon$ch, using diverse real-world use cases, that demonstrates its effectiveness. Pr$\epsilon\epsilon$ch provides transcriptions at a 2% to 32.25% (mean 17.34%) relative improvement in word error rate over Deep Speech, while fully obfuscating the speakers’ voice biometrics and allowing only a differentially private view of the textual content.
A demo of Pr$\epsilon\epsilon$ch can be found here.
Shimaa Ahmed, Amrita Roy Chowdhury, Kassem Fawaz, and Parmesh Ramanathan. Preech: A system for privacy-preserving speech transcription. In 29th USENIX Security Symposium (USENIX Security 20), pages 2703–2720. USENIX Association, Aug. 2020 [Pdf] [Slides] [USENIX Talk]
Project Velody: Resilient User Authentication by Nonlinear Vibration
We developed a novel solution, Velody, for user authentication in smart homes using unique vibration responses from users’ hands. Thanks to the nonlinear properties in hand-surface vibration, Velody can generate a large number of secret keys resilient to various attacks and accurately authenticate users in less than one second. This work is presented at ACM CCS 2019.

Li, Jingjie, Fawaz, Kassem and Kim, Younghyun, 2019, November. Velody: Nonlinear Vibration Challenge-Response for Resilient User Authentication. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security (pp. 1201-1213).
[Project] [PDF]
Face-Off: Adversarial Face Obfuscation
To help prevent users’ faces from being recognized with deep learning, we hide faces by applying imperceptible adversarial perturbations to uploaded faces. Face-Off uses the transferability property of adversarial examples to cause faces uploaded to proprietary face recognition platforms to be mislabeled. This way, users can still use face detection services, but do not have to be worried about their faces being associated with locations and activites, nor do users need to worry about their faces being scraped for training data.
Find our paper at https://arxiv.org/abs/2003.08861 See our web application at https://faceoff.xyz
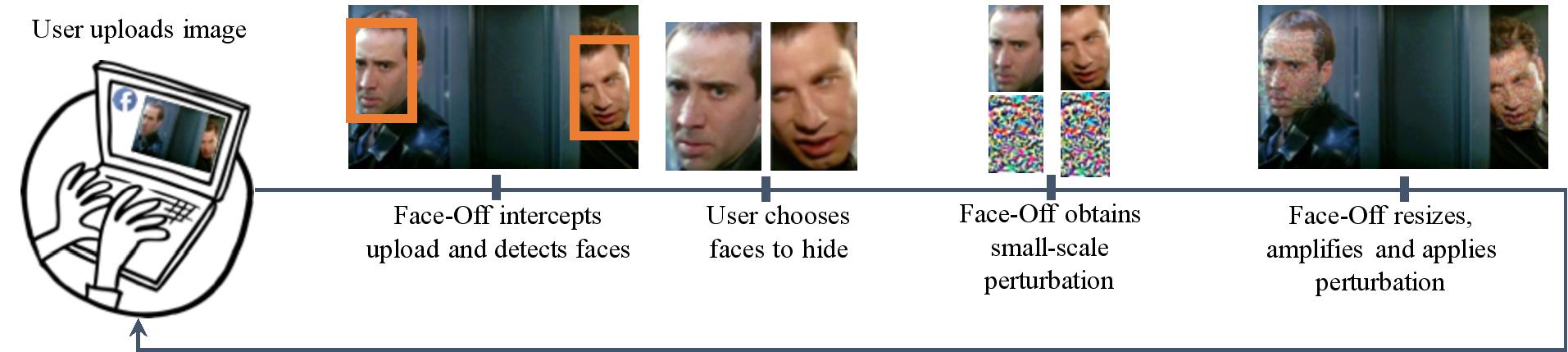 A high-level overview of Face-Off’s system.
A high-level overview of Face-Off’s system.