Abstract
Deceptive patterns in digital interfaces manipulate users into making unintended decisions, exploiting cognitive biases and psychological vulnerabilities. These patterns have become ubiquitous on various digital platforms. While efforts to mitigate deceptive patterns have emerged from legal and technical perspectives, a significant gap remains in creating usable and scalable solutions. We introduce our AutoBot framework to address this gap and help web stakeholders navigate and mitigate online deceptive patterns. AutoBot accurately identifies and localizes deceptive patterns from a screenshot of a website without relying on the underlying HTML code. AutoBot employs a two-stage pipeline that leverages the capabilities of specialized vision models to analyze website screenshots, identify interactive elements, and extract textual features. Next, using a large language model, AutoBot understands the context surrounding these elements to determine the presence of deceptive patterns. We also use AutoBot, to create a synthetic dataset to distill knowledge from ‘teacher’ LLMs to smaller language models. Through extensive evaluation, we demonstrate AutoBot’s effectiveness in detecting deceptive patterns on the web, achieving an F1-score of 0.93 in this task, underscoring its potential as an essential tool for mitigating online deceptive patterns.
We implement AutoBot, across three downstream applications targeting different web stakeholders: (1) a local browser extension providing users with real-time feedback, (2) a Lighthouse audit to inform developers of potential deceptive patterns on their sites, and (3) as a measurement tool for researchers and regulators.
How Off-the-Shelf LLMs Fall Short
While state-of-the-art vision-language models show promise in understanding visual content, directly applying them to detect deceptive patterns reveals significant limitations. These models often struggle with hallucination and lack of localization needed to identify deceptive patterns in real-world web interfaces.
These limitations motivated us to develop a specialized framework that combines vision and language models in a structured framework, rather than relying on end-to-end models that lack the precision required for this task.
The AutoBot Framework
AutoBot adopts a modular design, breaking down the task into two distinct modules: a Vision Module for element localization and feature extraction, and a Language Module for deceptive pattern detection. This approach allows AutoBot to work with screenshots alone, without requiring access to the underlying HTML code, which tends to be less stable across different webpage implementations.
Vision Module
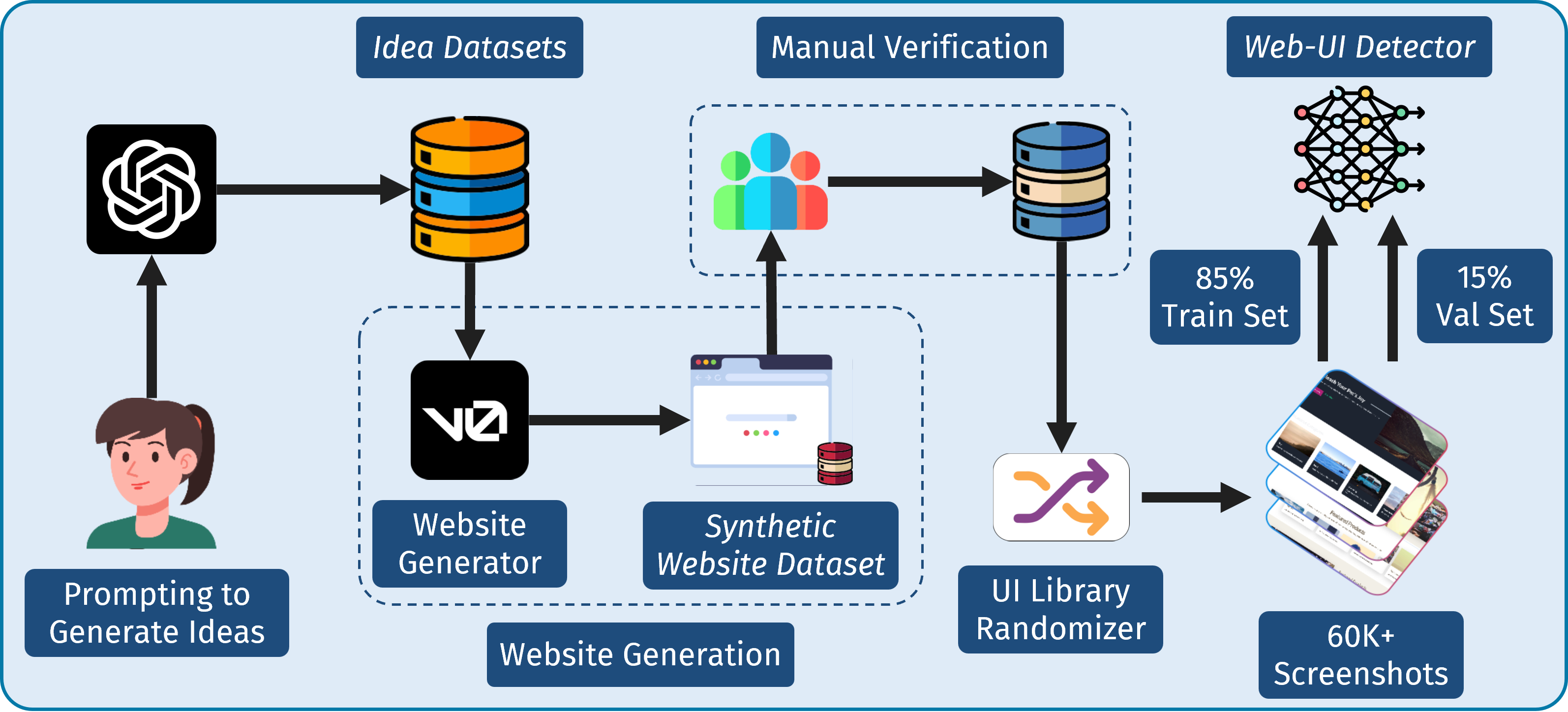
To address high false positive rates and localization issues, the Vision Module parses a webpage screenshot and maps it to a tabular representation we call ElementMap. As illustrated in the figure above, the ElementMap contains the text associated with each UI element, along with its features: element type, bounding box coordinates, font size, background color, and font color. For UI element detection, we train a YOLOv10 model on a synthetically generated dataset. The evaluation of our model is presented below.
Language Module
The Language Module takes the ElementMap as input and maps each element to a deceptive pattern from our taxonomy. This module reasons about each element considering its spatial context and visual features. We explore different instantiations of this module—such as distilling smaller models like Qwen and T5 from a larger teacher model like Gemini—to achieve various trade-offs in terms of cost, need for training, and accuracy.
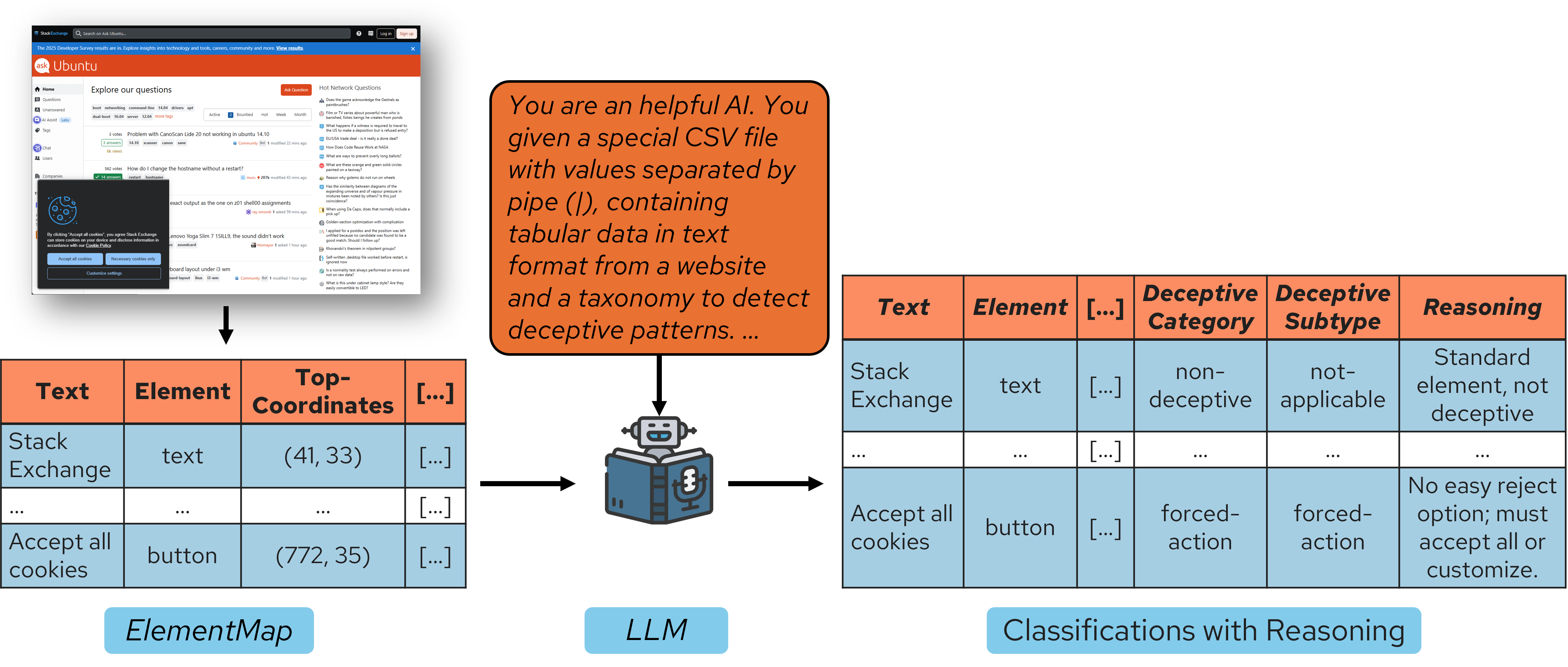
Knowledge Distillation
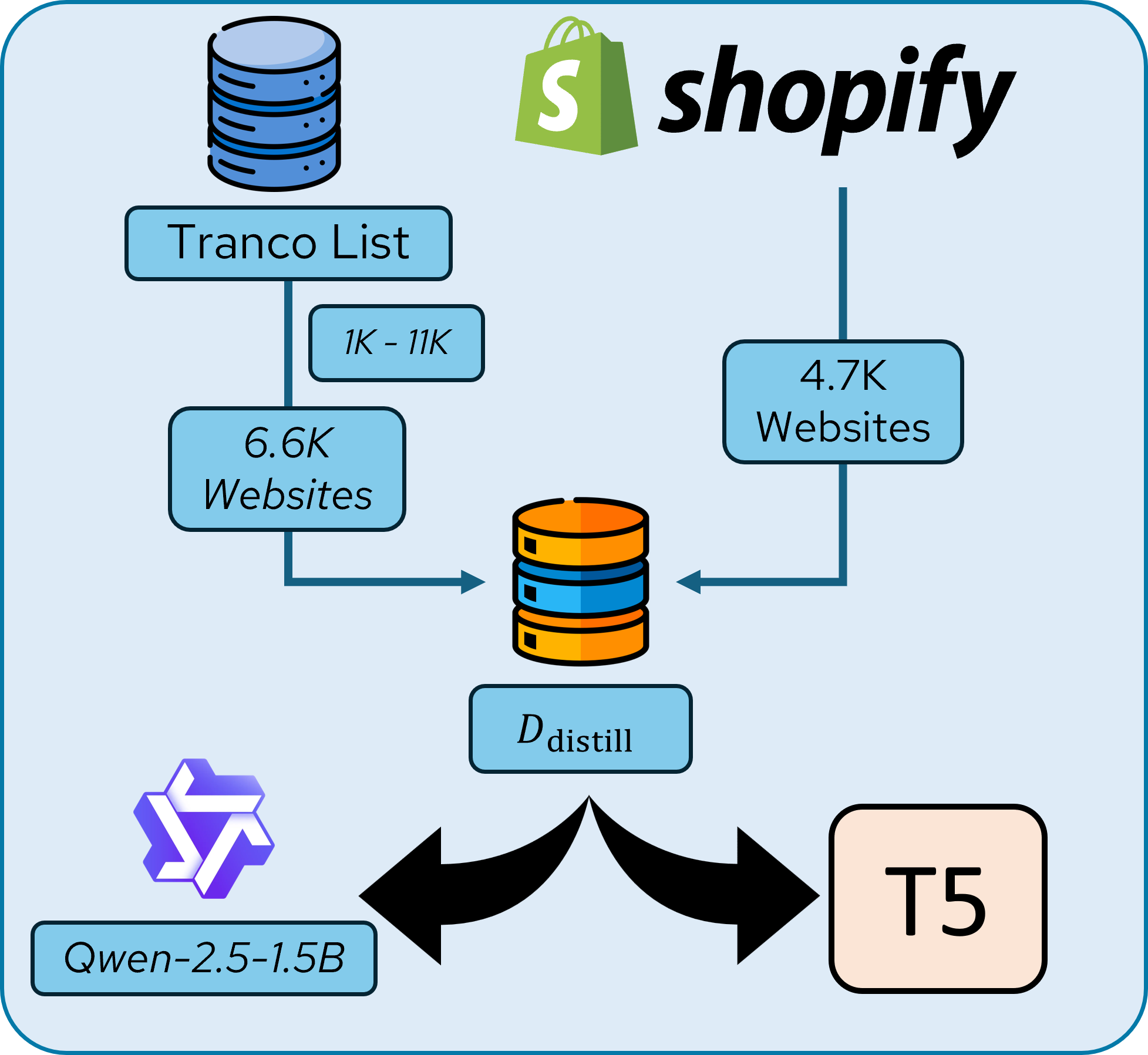
While large language models like Gemini achieve high accuracy in detecting deceptive patterns, using such closed-source models presents its own challenges such as high usage cost, considerable latency and potential data-privacy concerns. To address this, we employ knowledge distillation to create smaller, more efficient models that maintain strong detection performance while being faster and more cost-effective.
We leverage AutoBot with Gemini as the underlying language model to label deceptive patterns, we create a large-scale dataset of labeled examples, Ddistill. This synthetic dataset captures the teacher model's, i.e. Gemini's, classification along with it's reasoning for those classifications.
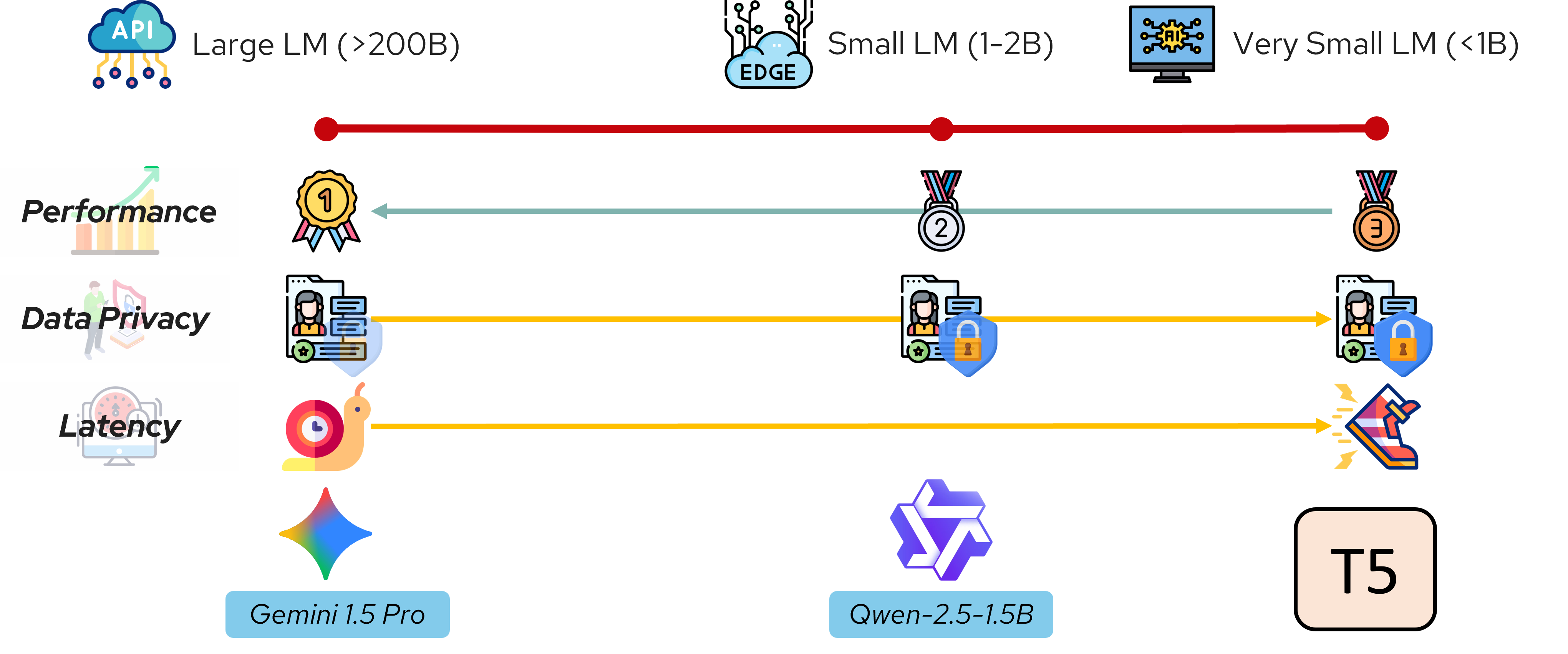
Using this dataset, Ddistill, we distill knowledge from the Gemini teacher model into two smaller student models: Qwen-2.5-1.5B and T5-base. The distillation process trains these models to replicate Gemini's pattern detection capabilities by learning from its predictions. This approach enables us to achieve different trade-offs across various metrics such as performance, data privacy, and latency.
E2E Evaluation
To quantify the trade-offs between these three model instantiations, we evaluate AutoBot’s end-to-end performance on deceptive pattern detection. The interactive visualizations below compare Gemini, distilled Qwen-2.5-1.5B, and distilled T5-base across our deceptive pattern taxonomy, demonstrating how each model choice affects detection accuracy, precision, and recall at both the category and subtype levels.